Use Data.
Preserve Privacy.
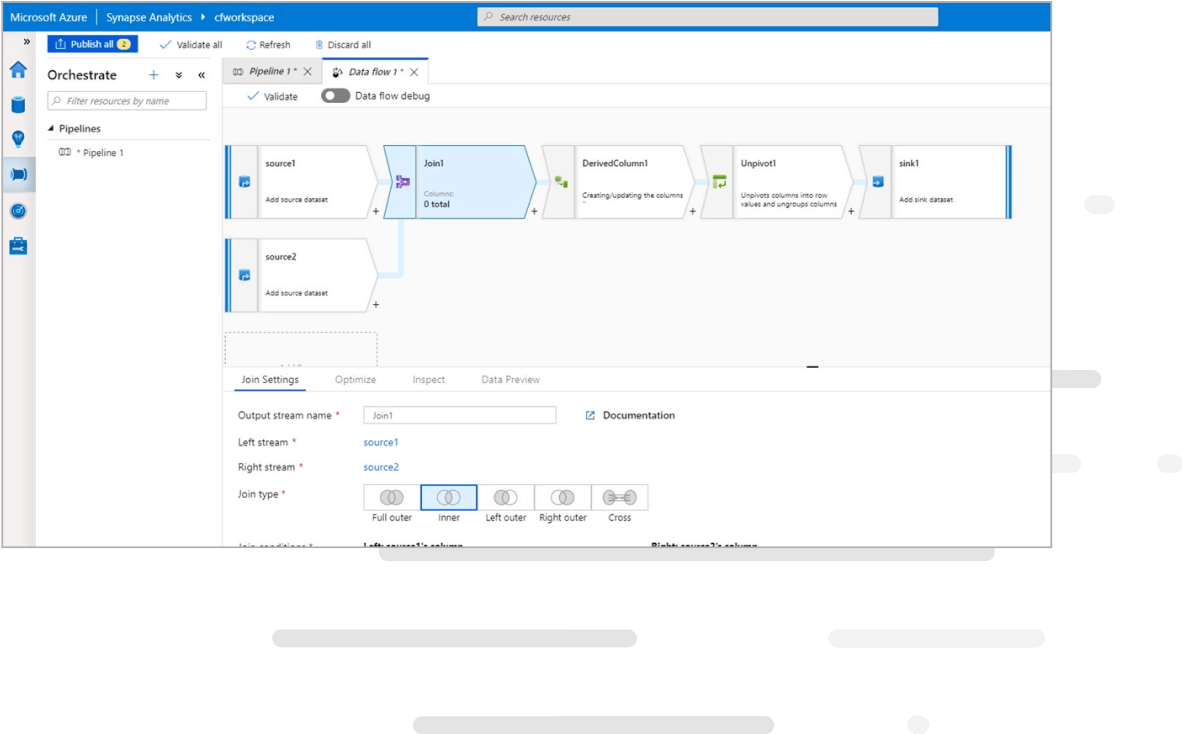
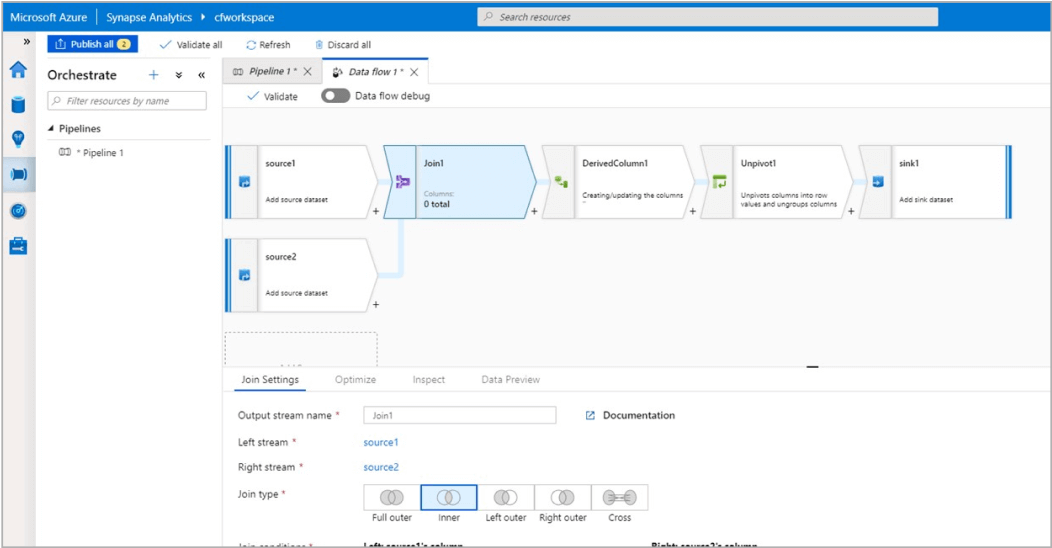
A differential privacy toolkit for analytics and machine learning
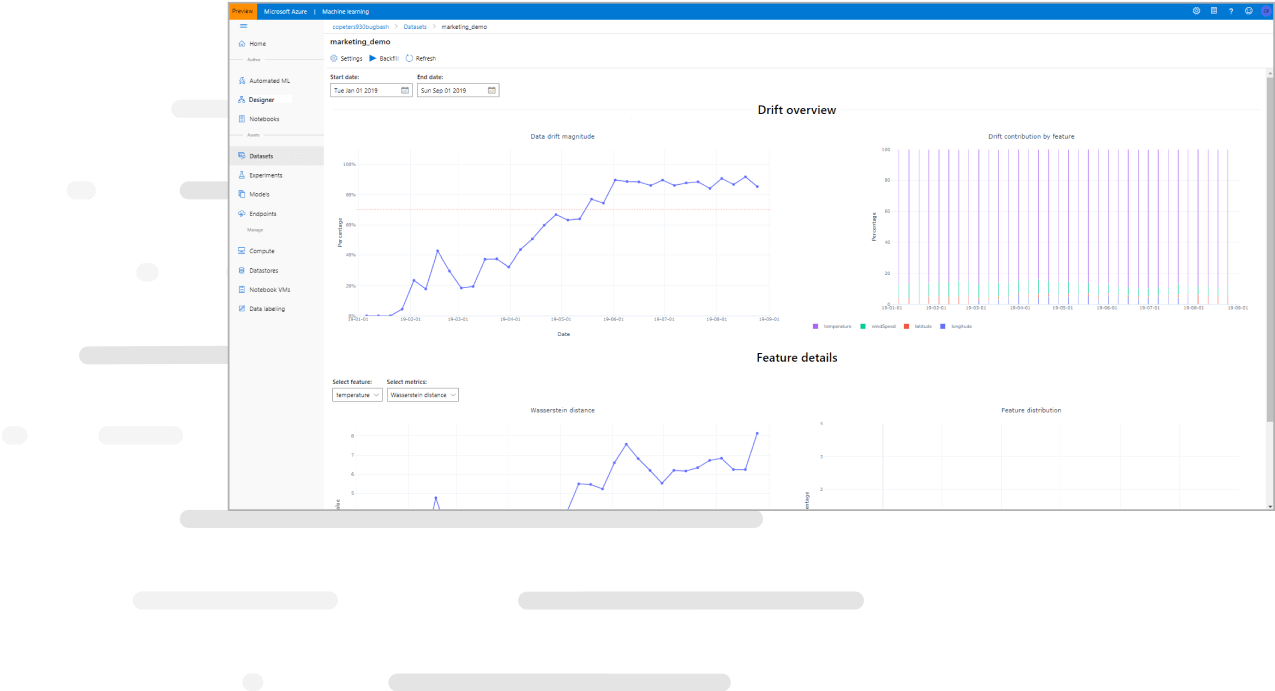
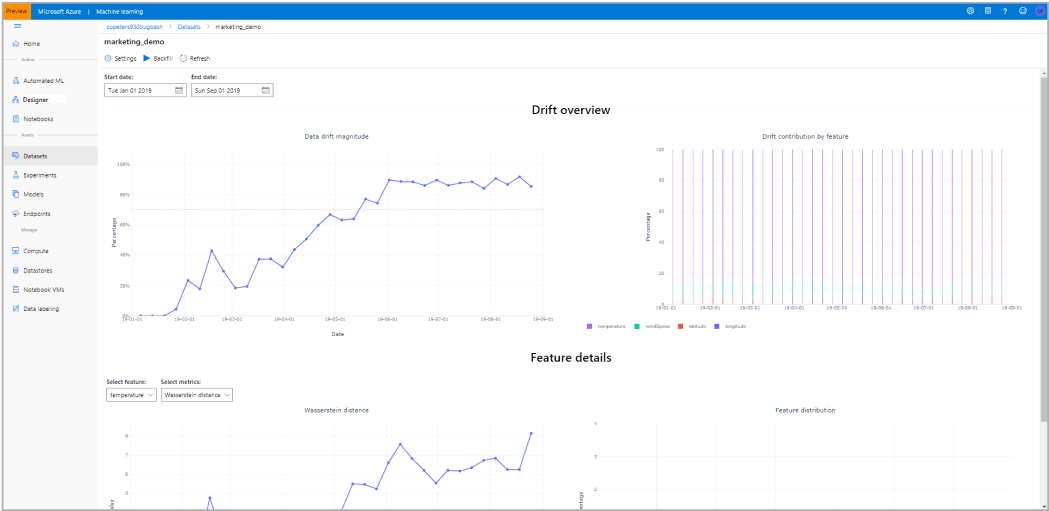
This toolkit uses state-of-the-art differential privacy (DP) techniques to inject noise into data, to prevent disclosure of sensitive information and manage exposure risk.